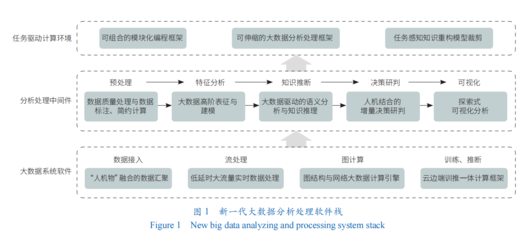
在当今信息爆炸的时代,数据已成为驱动社会进步和商业创新的核心生产要素。面对海量、多源、异构、高速的数据洪流,传统的数据分析处理方法已显得力不从心,构建一个适应新时代需求的大数据分析处理技术新体系,已成为学术界和产业界共同关注的重要课题。本文旨在探讨这一新体系的内涵、关键技术与未来发展方向。
一、新体系的内涵与驱动力
大数据分析处理技术新体系,是指在数据规模、复杂性及实时性要求日益增长的背景下,融合了分布式计算、人工智能、云计算、边缘计算等前沿技术,以支持从数据采集、存储、处理、分析到价值呈现全链路高效、智能、可扩展的一体化技术架构与方法论。其核心驱动力源于以下几个方面:
- 数据范式的转变:数据来源从单一结构化数据库扩展到互联网、物联网、社交网络、日志文件等多源异构数据,数据形态也从静态的“数据仓库”向动态的“数据湖”、“数据湖仓一体”演进。
- 业务需求的升级:从传统的描述性分析(发生了什么)和诊断性分析(为什么发生),向预测性分析(将会发生什么)和规范性分析(应该做什么)迈进,对实时决策、智能推荐、风险预警等能力的要求越来越高。
- 技术融合的深化:计算模式从批处理(如Hadoop MapReduce)向流批一体(如Flink)、图计算、交互式查询等多元化发展,并与机器学习、深度学习模型训练与推理紧密集成,形成数据智能闭环。
二、新体系的关键技术支柱
构建这一新体系,需要依托几大关键技术支柱的协同创新:
- 存算分离与云原生架构:为了应对弹性伸缩和成本优化的挑战,存算分离成为主流设计。数据存储在可无限扩展、成本低廉的对象存储中,而计算资源(CPU、GPU)则根据任务需求动态调度。结合容器化、微服务和Kubernetes编排的云原生技术,使整个系统具备了高度的敏捷性、弹性和可运维性。
- 流批一体与实时处理引擎:打破批处理与流处理的界限,实现同一套API和语义下的统一处理,是满足实时业务的关键。以Apache Flink为代表的流批一体引擎,能够以毫秒级延迟处理无界数据流,同时支持有界数据集的高吞吐批处理,为实时分析、风控、监控等场景提供统一技术底座。
- AI与数据处理的深度融合(Data+AI):数据处理流程不再是简单的ETL(提取、转换、加载),而是与AI模型的生命周期管理深度耦合。这包括:
- 特征工程平台化:自动化特征发现、生成与管理。
- 模型训练与服务的无缝衔接:数据处理管道直接为模型训练准备数据,并将模型推理结果快速反馈到业务系统。
- 隐私计算与联邦学习:在保证数据隐私和安全的前提下,实现跨组织、跨域的数据价值挖掘。
- 智能数据治理与数据编织(Data Fabric):面对海量、分散的数据资产,自动化、智能化的数据治理至关重要。数据编织作为一种新兴的架构方法,利用元数据、知识图谱、机器学习等技术,实现数据的自动发现、编目、血缘分析、质量监控和自助式服务,让数据更易找、可信、好用。
- 边缘-云协同计算:随着物联网的普及,大量数据在终端和边缘侧产生。新体系需要支持在边缘设备上进行轻量级、低延迟的数据预处理和实时分析,再将聚合结果或模型更新同步至云端进行深度分析与全局优化,形成高效的协同计算网络。
三、未来展望与挑战
大数据分析处理技术新体系将朝着更智能、更融合、更普惠的方向发展:
- 智能化:AI将更深层次地融入数据处理的各个环节,实现从“人找数据、人分析”到“数据找人、自动分析”的转变,提升决策效率。
- 融合化:技术栈将进一步收敛,形成集数据集成、存储、计算、分析、AI、应用于一体的“一站式”平台,降低技术复杂度。
- 普惠化:通过低代码/无代码、自然语言交互等方式,降低数据分析的技术门槛,让业务人员也能直接参与数据价值的挖掘。
新体系的构建也面临诸多挑战,如数据安全与隐私保护的刚性约束日益增强、跨云跨地域数据管理的复杂性、海量计算带来的能耗问题(绿色计算),以及复合型数据人才的短缺等。
###
大数据分析处理技术新体系的构建是一场深刻的变革。它不仅是技术的迭代升级,更是思维模式和组织方式的革新。只有以业务价值为导向,以开放融合的技术生态为支撑,并高度重视数据治理与安全,才能驾驭数据洪流,真正释放大数据的巨大潜能,赋能千行百业的数字化转型与智能化升级。